本文主要介绍页面加载相关的三个部分:加载流程解析,影响性能的因素,优化的方法
加载流程
流程简介
对用户来说,访问页面相当简单:
1
打开浏览器 --> 输入网址 --> 浏览页面
但对于浏览器来说,它与服务端之间的交互要复杂的多。通过浏览器的api(window.performance.timing),我们可以详细的画出一个请求的完成流程:
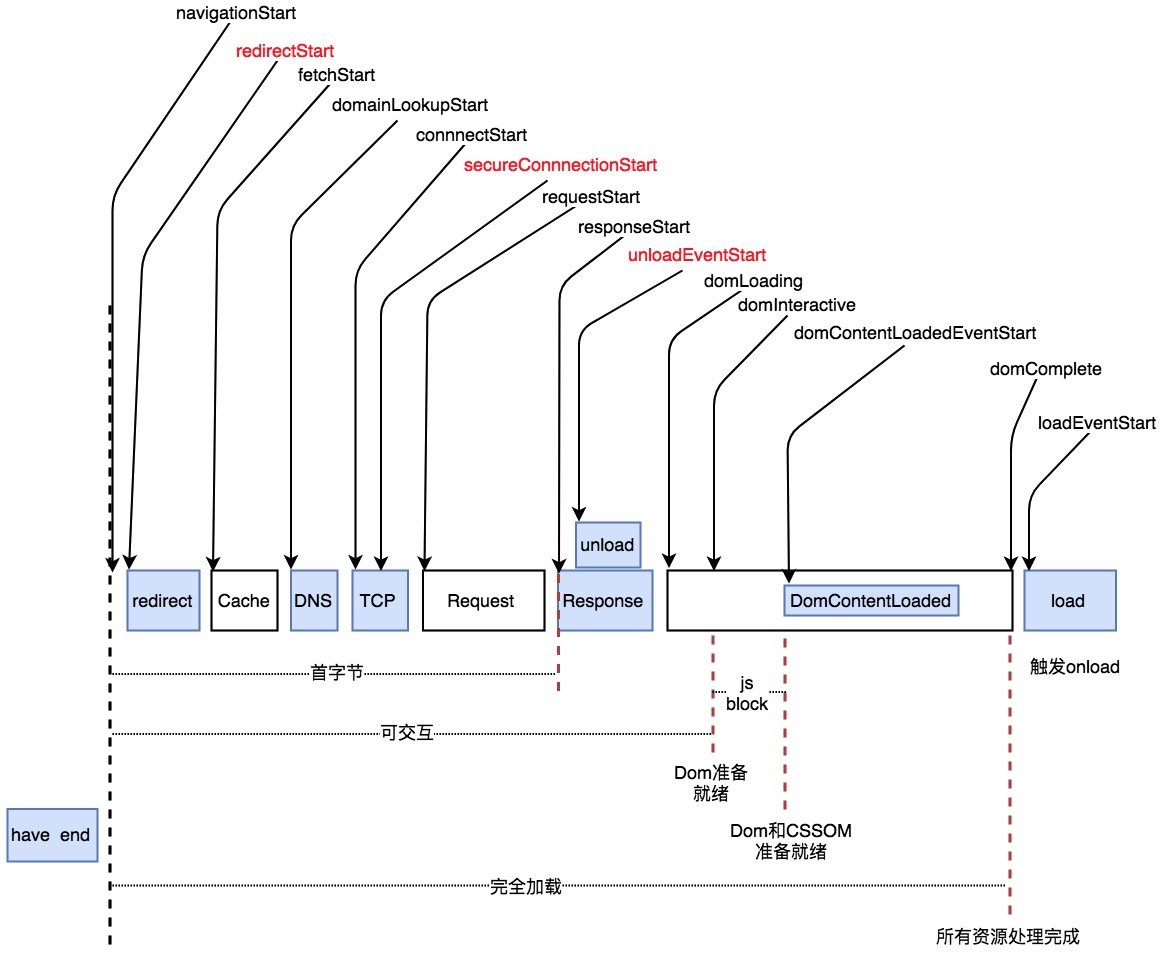
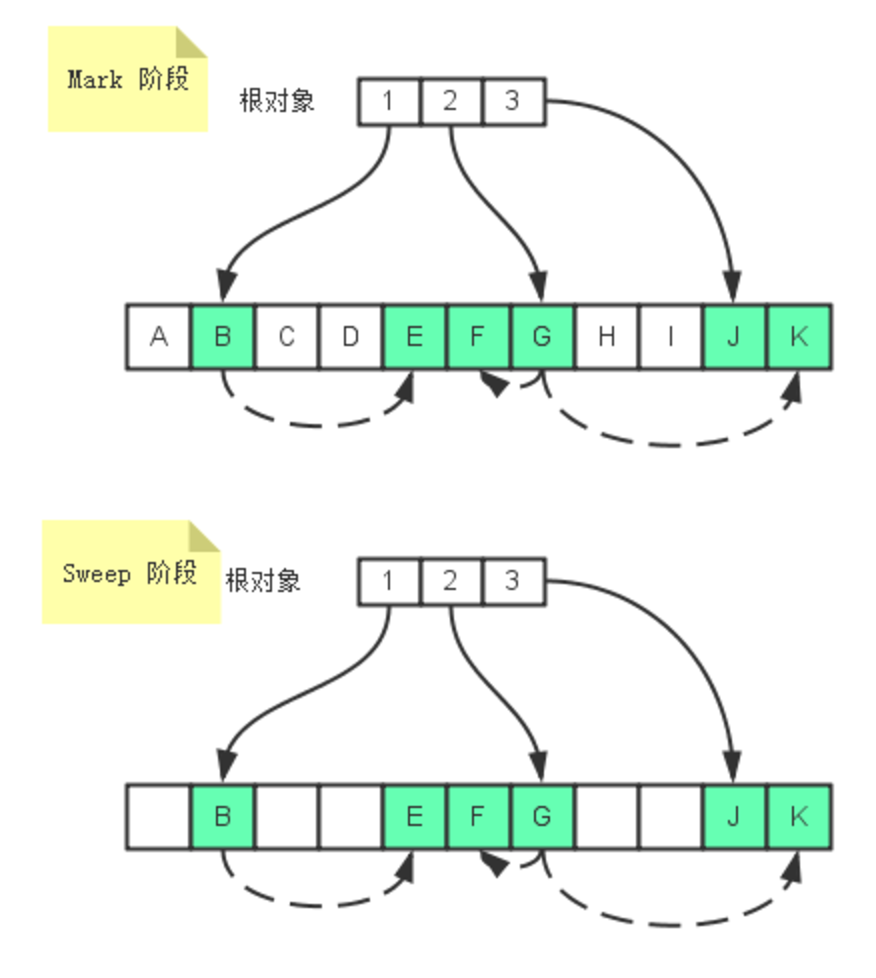
- 图1显示的是完整的加载流程,事件基本按所示顺序触发
- domLoading可能在ResponseEnd之前触发
- unload有可能在ResponseStart之前触发
- 部分事件是可选的,默认值为0。如Redirect、Unload和secureConnectionStart(红色),实际请求时有可能不会触发
- redirectStart/redirectEnd:没有重定向时,这两个字段值均为0
- secureConnectionStart:非HTTPS时,字段值为0
- unloadEventStart/unloadEventEnd:如果之前没有同源的document,字段值为0
- 部分模块(浅蓝)事件有起止点,其他模块只有起点
流程解析
完整的流程可以分为两个阶段:请求和渲染
- 请求阶段:从开始请求到获取服务端数据。简单来说就是图1中的首字节,或者再加上response。核心流程包含五部分:
- 重定向:重定向后需要加载新页面。对浏览器来说,新页面加载时间从redirectStart开始。对用户来说,显示时间为重定向前后页面之和
- 缓存:浏览器已缓存的资源,不用重新发网络请求,直接从缓存中拉取
- DNS:域名解析,可以缓存
- TCP:建立TCP连接
- Request:未有效缓存或新资源,向服务端发起请求
- 渲染阶段:浏览器接收数据后的处理,最终呈现用户可见页面。可以理解为domLoading事件之后的阶段,先后顺序依次为:
- Dom就绪:Html解析,构建DOM Tree。触发domInteractive
- Dom和Cssom就绪:DCL(domContentLoaded),开始构建Render Tree。触发domContentLoadedEventStart,domContentLoadedEventEnd所有事件绑定完成
- 所有资源就绪:页面上所有资源加载完成,包含图片、视频等。触发domComplete
渲染阶段在webkit浏览器(chrome & safari)中实际执行流程如图2所示: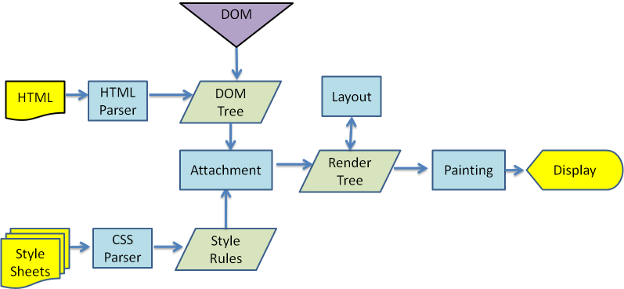
- 可以看到,HTML和CSS的解析是同步进行的。Render Tree会在DOM Tree后立即触发,表现为domContentLoadedEventStart - domInteractive的差值很小。
- 但是,由于JS可能操作HTML,故会中断DOM Tree的构建。JS在执行时,有时会依赖样式。所以JS会减慢Dom的解析,JS需要等待CSSOM的解析,如图3所示。为了解决这种问题,有两种方法可以延迟JS的执行:
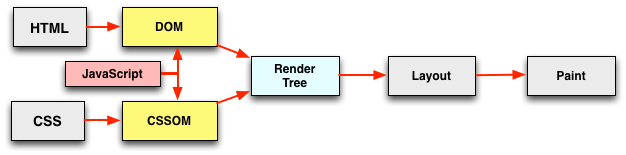
图3 - JS设置为defer,domInteractive不需等待JS而正常触发,但会在DCL触发之前被执行
- JS设置为async,domInteractive和DCL都不需等待JS的执行
但无论JS是defer或者async,都需要保证JS中不执行doc.write,并且CSSOM在JS执行之前构建。
性能因素
- 浏览器
- 请求处理
- 渲染
- 缓存
- 网络
- 状态
- 协议
- 传输内容
- 服务端
- 并发
- 请求响应
- 编码
性能监控
- 浏览器的api查看各个事件触发的时间
1
2performance.timing
performance.getEntriesByType("navigation")[0] // new api
以上获取的都是时间戳,通过简单的计算,可得到实际耗时1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37var res = {};
var timing = window.performance.timing;
var start = timing['navigationStart'] || 0;
for (var key in timing) {
if (typeof timing[key] == 'number') {
if (timing[key] === 0) {
switch(key) {
case 'redirectStart' :
console.log('无重定向');
break;
case 'unloadEventStart' :
console.log('没有unload事件:直接输入url或从其他域跳转');
break;
case 'secureConnectionStart' :
console.log('非HTTPS请求');
break;
}
} else {
res[key] = timing[key] - start;
}
}
}
// print in sequence
while(true) {
var key = 'loadEventEnd';
var min = res[key];
for (var i in res) {
if (res[i] < min) {
min = res[i];
key = i;
}
}
console.log(`${key} : ${res[key]}`)
delete res[key];
if (key == 'loadEventEnd') break;
}
优化方式
针对影响网站服务的各种因素和限制,分别优化:
减少请求次数
- 合并静态文件css、js等
- 雪碧图 VS 内联图片(base64)
- 内容有所变动,雪碧图就要全部调整
- 内联图片不能缓存
- 避免重定向
- 重定向可以跟踪出站流量 http://xxx.com?url=jump_url
- 响应头部添加Strict-Transport-Security: max-age=31536000,可避免http -> https的重定向
- 使用内联脚本、样式
- 主页可用
- 脚本或样式复用率低,可用
- 复用率高的页面建议使用外部脚本或样式
- 组件即可内联,又可复用(React,Vue等)
浏览器缓存
缓存使用示例
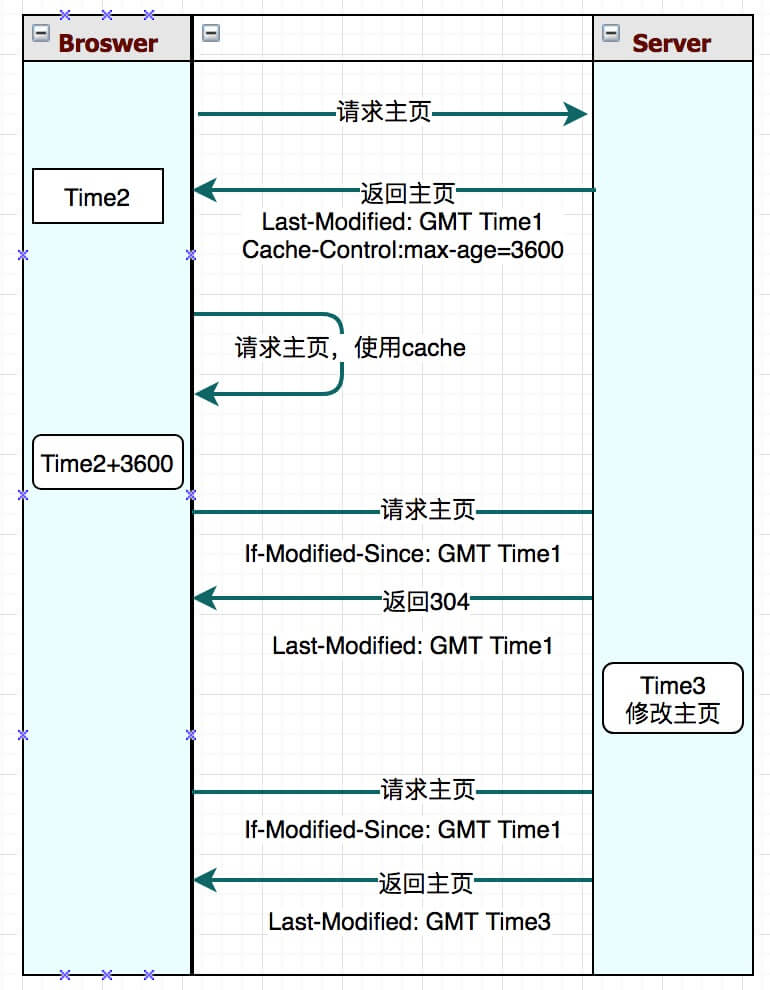
图4 常用缓存字段列表
request | response | method | content | comment
—|—|—|—|—
If-Modified-Since: time1 | Last-Modified: time2 | get or head | Tue, 12 Sep 2017 08:59:08 GMT | 是否过期,没过期返回304,会被If-None-Match覆盖
If-None-Match | ETag | | 指纹 | 资源无变化,GET或HEAD返回304,其他方法返回412;If-Match PUT方法用来更新资源
| Expires| | Tue, 12 Sep 2017 08:59:08 GMT | 某个时间后失效,有效期内直接使用缓存。需要和服务端对时,会被Cache-Control:max-age覆盖
Cache-Control | Cache-Control| | must_revalidate, public, max-age=3600 | no-cache,no-stroe,max-age(一段周期后失效)等,在http 1.1引入合理设置缓存
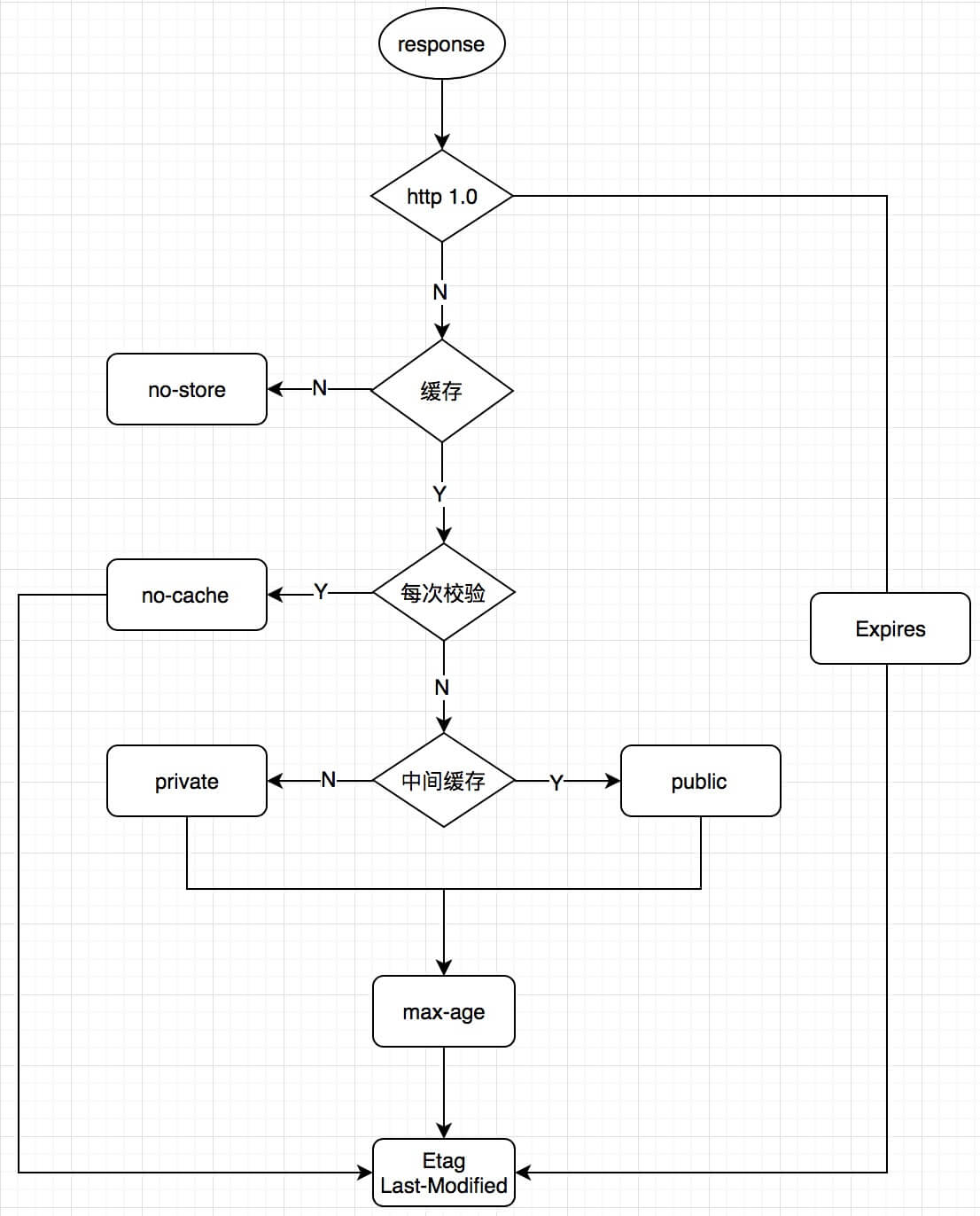
图5
减小请求文件
- 支持压缩(传输,浏览器解压)
- Request: Accept-Encoding:gzip, deflate, sdch, br
- Response: Content-Encoding:gzip
- Response: vary: Accept-Encoding(代理商)
- 压缩静态资源文件
- 使用合适的图片
缩短请求路径
- CDN(内容分发网络)
- 减少DNS查找(域名尽量少)
- 使用HTTP,而不是HTTPS(安全性)
- 长连接 (connection:keep-alive)
- 同一TCP连接,可以发送多个请求
- Transfer-Encoding: chunked,chunked长度为0,本次连接终止
节省渲染时间
- 样式
- 样式放在顶部(DCL:防止闪烁、白屏等)
- 少使用@import,会同步导入css文件
- 避免css表达式
- 脚本
- 脚本放在底部,会阻塞其他资源的下载(白屏等)
- 按需加载
请求并发
- Domain sharding
- 浏览器只能对同一Domain最多请求6~8个连接,资源分散(DNS查找)
- Pipelining
- 同时发送多个请求,但是服务端依然需要依次响应
http2
- 简介(移步查看更多http2)
- 压缩header,header不再使用字段,使用位标识
- 服务端推送
- frame和stream
- 每个请求或应答相当于一个stream(id:奇数为客户端)
- 响应数据(stream)切成多个帧frame(所属stream id),可交叉传送
- 流优先级和依赖