背景
前端渲染有很多框架,而且形式和内容在不断发生变化。这些演变的背后是设计模式的变化,而归根到底是功能划分逻辑的演变:MVC—>MVP—>MVVM(忽略最早混在一起的写法,那不称为模式)。近几年兴起的React、Vue、Angular等框架都属于MVVM模式,能帮我们实现界面渲染、事件绑定、路由分发等复杂功能。但在一些只需完成数据和模板简单渲染的场合,它们就显得笨重而且学习成本较高了。
例如,在美团外卖的开发实践中,前端经常从后端接口取得长串的数据,这些数据拥有相同的样式模板,前端需要将这些数据在同一个样式模板上做重复渲染操作。
解决这个问题的模板引擎有很多,doT.js(出自女程序员Laura Doktorova之手)是其中非常优秀的一个。下表将doT.js与其他同类引擎做了对比:
| 框架 | 大小 | 压缩版本大小 | 迭代 | 条件表达式 | 自定义语法 |
|---|---|---|---|---|---|
| doT.js | 6KB | 4KB | √ | √ | √ |
| mustache | 18.9 KB | 9.3 KB | √ | × | √ |
| Handlebars | 512KB | 62.3KB | √ | √ | √ |
| artTemplate(腾讯) | - | 5.2KB | √ | √ | √ |
| BaiduTemplate(百度) | 9.45KB | 6KB | √ | √ | √ |
| jQuery-tmpl | 18.6KB | 5.98KB | √ | √ | √ |
可以看出,doT.js表现突出。而且,它的性能也很优秀,本人在Mac Pro上的用Chrome浏览器(版本为:56.0.2924.87)上做100条数据10000次渲染性能测试,结果如下:
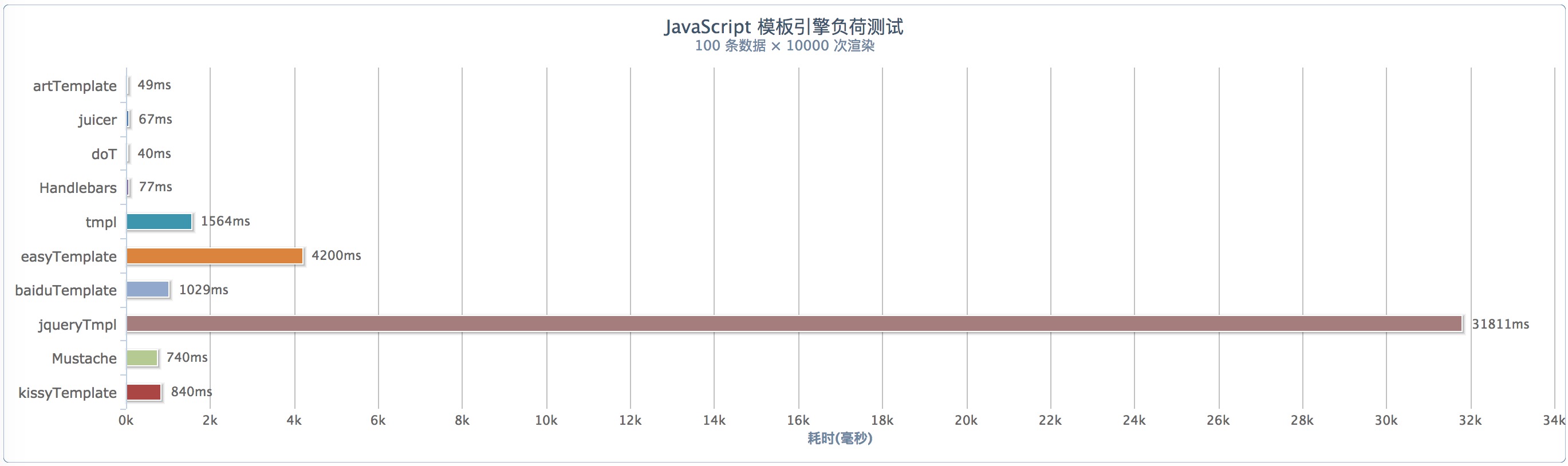
从上可以看出doT.js更值得推荐,它的主要优势在于:
- 小巧精简,源代码不超过两百行,6KB的大小,压缩版只有4KB;
- 支持表达式丰富,涵盖几乎所有应用场景的表达式语句;
- 性能优秀;
- 不依赖第三方库。
本文主要对doT.js的源码进行分析,探究一下这类模板引擎的实现原理。
如何使用
如果之前用过doT.js,可以跳过此小节,doT.js使用示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<script type="text/html" id="tpl">
<div>
<a>name:{{= it.name}}</a>
<p>age:{{= it.age}}</p>
<p>hello:{{= it.sayHello() }}</p>
<select>
{{~ it.arr:item}}
<option {{?item.id == it.stringParams2}}selected{{?}} value="{{=item.id}}">
{{=item.text}}
</option>
{{~}}
</select>
</div>
</script>
<script>
$("#app").html(doT.template($("#tpl").html())({
name:'stringParams1',
stringParams1:'stringParams1_value',
stringParams2:1,
arr:[{id:0,text:'val1'},{id:1,text:'val2'}],
sayHello:function () {
return this[this.name]
}
}));
</script>
可以看出doT.js的设计思路:将数据注入到预置的视图模板中渲染,返回HTML代码段,从而得到最终视图。
下面是一些常用语法表达式对照表:
1 | 项目 | JavaScript语法 | 对应语法 | 案例 |
源码分析及实现原理
和后端渲染不同,doT.js的渲染完全交由前端来进行,这样做主要有以下好处:
- 脱离后端渲染语言,不需要依赖后端项目的启动,从而降低了开发耦合度、提升开发效率;
- View层渲染逻辑全在JavaScript层实现,容易维护和修改;
- 数据通过接口得到,无需考虑后端数据模型变化,只需关心数据格式。
doT.js源码核心:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40...
// 去掉所有制表符、空格、换行
str = ("var out='" + (c.strip ? str.replace(/(^|\r|\n)\t* +| +\t*(\r|\n|$)/g," ")
.replace(/\r|\n|\t|\/\*[\s\S]*?\*\//g,""): str)
.replace(/'|\\/g, "\\$&")
.replace(c.interpolate || skip, function(m, code) {
return cse.start + unescape(code,c.canReturnNull) + cse.end;
})
.replace(c.encode || skip, function(m, code) {
needhtmlencode = true;
return cse.startencode + unescape(code,c.canReturnNull) + cse.end;
})
// 条件判断正则匹配,包括if和else判断
.replace(c.conditional || skip, function(m, elsecase, code) {
return elsecase ?
(code ? "';}else if(" + unescape(code,c.canReturnNull) + "){out+='" : "';}else{out+='") :
(code ? "';if(" + unescape(code,c.canReturnNull) + "){out+='" : "';}out+='");
})
// 循环遍历正则匹配
.replace(c.iterate || skip, function(m, iterate, vname, iname) {
if (!iterate) return "';} } out+='";
sid+=1; indv=iname || "i"+sid; iterate=unescape(iterate);
return "';var arr"+sid+"="+iterate+";if(arr"+sid+"){var "+vname+","+indv+"=-1,l"+sid+"=arr"+sid+".length-1;while("+indv+"<l"+sid+"){"
+vname+"=arr"+sid+"["+indv+"+=1];out+='";
})
// 可执行代码匹配
.replace(c.evaluate || skip, function(m, code) {
return "';" + unescape(code,c.canReturnNull) + "out+='";
})
+ "';return out;")
...
try {
return new Function(c.varname, str);//c.varname 定义的是new Function()返回的函数的参数名
} catch (e) {
/* istanbul ignore else */
if (typeof console !== "undefined") console.log("Could not create a template function: " + str);
throw e;
}
...
这段代码总结起来就是一句话:用正则表达式匹配预置模板中的语法规则,将其转换、拼接为可执行HTML代码,作为可执行语句,通过new Function()创建的新方法返回。
代码解析重点1:正则替换
正则替换是doT.js的核心设计思路,本文不对正则表达式做扩充讲解,仅分析doT.js的设计思路。先来看一下doT.js中用到的正则:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16templateSettings: {
evaluate: /\{\{([\s\S]+?(\}?)+)\}\}/g, //表达式
interpolate: /\{\{=([\s\S]+?)\}\}/g, // 插入的变量
encode: /\{\{!([\s\S]+?)\}\}/g, // 在这里{{!不是用来做判断,而是对里面的代码做编码
use: /\{\{#([\s\S]+?)\}\}/g,
useParams: /(^|[^\w$])def(?:\.|\[[\'\"])([\w$\.]+)(?:[\'\"]\])?\s*\:\s*([\w$\.]+|\"[^\"]+\"|\'[^\']+\'|\{[^\}]+\})/g,
define: /\{\{##\s*([\w\.$]+)\s*(\:|=)([\s\S]+?)#\}\}/g,// 自定义模式
defineParams:/^\s*([\w$]+):([\s\S]+)/, // 自定义参数
conditional: /\{\{\?(\?)?\s*([\s\S]*?)\s*\}\}/g, // 条件判断
iterate: /\{\{~\s*(?:\}\}|([\s\S]+?)\s*\:\s*([\w$]+)\s*(?:\:\s*([\w$]+))?\s*\}\})/g, // 遍历
varname: "it", // 默认变量名
strip: true,
append: true,
selfcontained: false,
doNotSkipEncoded: false // 是否跳过一些特殊字符
}
源码中将正则定义写到一起,这样方便了维护和管理。在早期版本的doT.js中,处理条件表达式的方式和tmpl一样,采用直接替换成可执行语句的形式,在最新版本的doT.js中,修改成仅一条正则就可以实现替换,变得更加简洁。
doT.js源码中对模板中语法正则替换的流程如下:

代码解析重点2:new Function()运用
函数定义时,一般通过Function关键字,并指定一个函数名,用以调用。在JavaScript中,函数也是对象,可以通过函数对象(Function Object)来创建。正如数组对象对应的类型是Array,日期对象对应的类型是Date一样,如下所示:1
var funcName = new Function(p1,p2,...,pn,body);
参数的数据类型都是字符串,p1到pn表示所创建函数的参数名称列表,body表示所创建函数的函数体语句,funcName就是所创建函数的名称(可以不指定任何参数创建一个匿名函数)。
下面的定义是等价的。
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 一般函数定义方式
function func1(a,b){
return a+b;
}
// 参数是一个字符串通过逗号分隔
var func2 = new Function('a,b','return a+b');
// 参数是多个字符串
var func3 = new Function('a','b','return a+b');
// 一样的调用方式
console.log(func1(1,2));
console.log(func2(2,3));
console.log(func3(1,3));
// 输出
3 // func1
5 // func2
4 // func3
从上面的代码中可以看出,Function的最后一个参数,被转换为可执行代码,类似eval的功能。eval执行时存在浏览器性能下降、调试困难以及可能引发XSS(跨站)攻击等问题,因此不推荐使用eval执行字符串代码,new Function()恰好解决了这个问题。回过头来看doT代码中的”new Function(c.varname, str)”,就不难理解varname是传入可执行字符串str的变量。
具体关于new Fcuntion的定义和用法,详细请阅读Function详细介绍。
性能之因
读到这里可能会产生一个疑问:doT.js的性能为什么在众多引擎如此突出?通过阅读其他引擎源代码,发现了它们核心代码段中都存在这样那样的问题。
jQuery-tmpl
1 | function buildTmplFn( markup ) { |
在上面的代码中看到,jQuery-teml同样使用了new Function()的方式编译模板,但是在性能对比中jQuery-teml性能相比doT.js相差甚远,出现性能瓶颈的关键在于with语句的使用。
with语句为什么对性能有这么大的影响?我们来看下面的代码:1
2
3
4
5
6
7
8
9
10
11
12var datas = {persons:['李明','小红','赵四','王五','张三','孙行者','马婆子'],gifts:['平民','巫师','狼','猎人','先知']};
function go(){
with(datas){
var personIndex = 0,giftIndex = 0,i=100000;
while(i){
personIndex = Math.floor(Math.random()*persons.length);
giftIndex = Math.floor(Math.random()*gifts.length)
console.log(persons[personIndex] +'得到了新的身份:'+ gifts[giftIndex]);
i--;
}
}
}
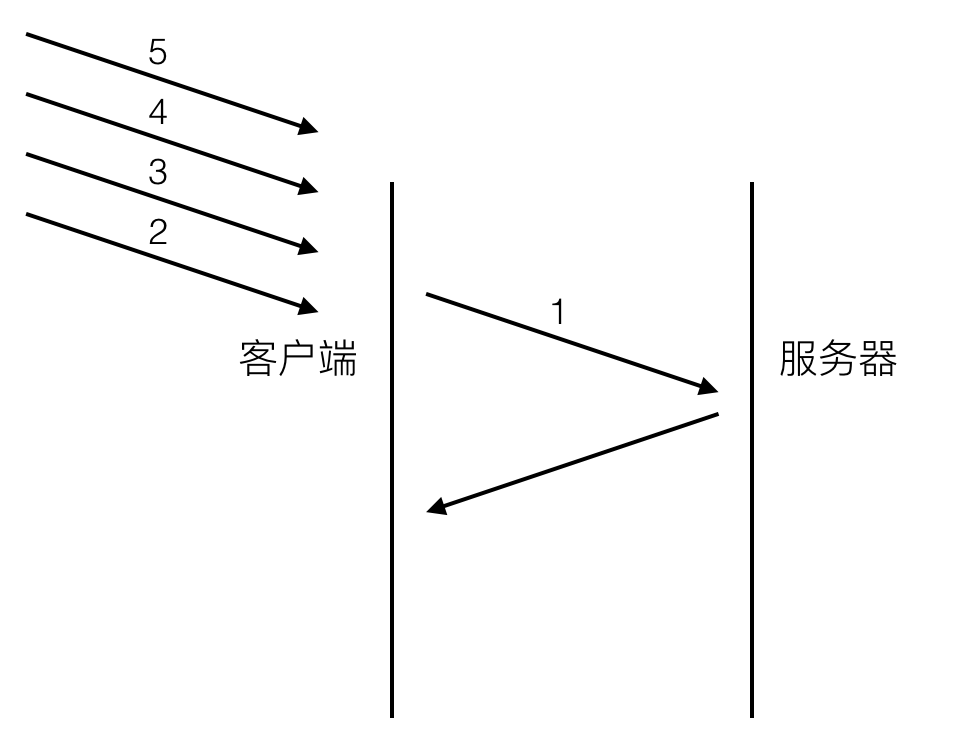
上面代码中使用了一个with表达式,为了避免多次从datas中取变量而使用了with语句。这看起来似乎提升了效率,但却产生了一个性能问题:在JavaScript中执行方法时会产生一个执行上下文,这个执行上下文持有该方法作用域链,主要用于标识符解析。当代码流执行到一个with表达式时,运行期上下文的作用域链被临时改变了,一个新的可变对象将被创建,它包含指定对象的所有属性。此对象被插入到作用域链的最前端,意味着现在函数的所有局部变量都被推入第二个作用域链对象中,这样访问datas的属性非常快,但是访问局部变量的速度却变慢了,所以访问代价更高了,如下图所示。
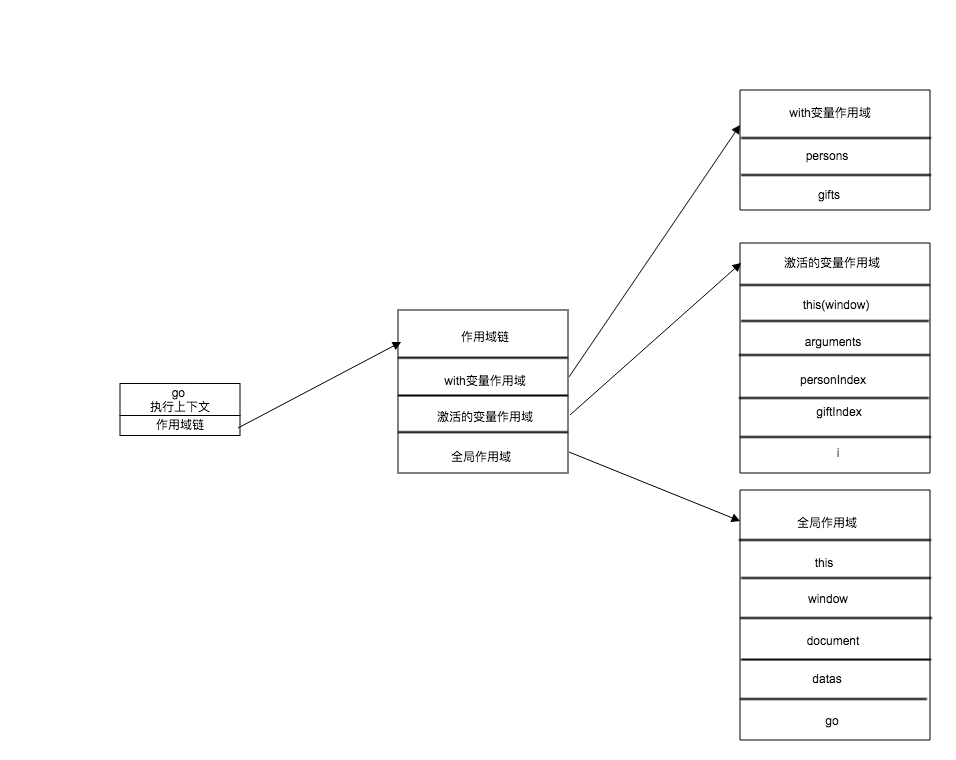
这个插件在GitHub上面介绍时,作者Boris Moore着重强调两点设计思路:
- 模板缓存,在模板重复使用时,直接使用内存中缓存的模板。在本文作者看来,这是一个鸡肋的功能,在实际使用中,无论是直接写在String中的模板还是从Dom获取的模板都会以变量的形式存放在内存中,变量使用得当,在页面整个生命周期内都能取到这个模板。通过源码分析之后发现jQuery-tmpl的模板缓存并不是对模板编译结果进行缓存,并且会造成多次执行渲染时产生多次编译,再加上代码with性能消耗,严重拖慢整个渲染过程。
- 模板标记,可以从缓存模板中取出对应子节点。这是一个不错的设计思路,可以实现数据改变只重新渲染局部界面的功能。但是我觉得:模板将渲染结果交给开发者,并渲染到界面指定位置之后,模板引擎的工作就应该结束了,剩下的对节点操作应该灵活的掌握在开发者手上。
不改变原来设计思路基础之上,尝试对源代码进行性能提升。
先保留提升前性能作为对比:

首先来我们做第一次性能提升,移除源码中with语句。
第一次提升后:
接下来第二部提升,落实Boris Moore设计理念中的模板缓存:

优化后的这一部分代码段被我们修改成了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21function buildTmplFn( markup ) {
if(!compledStr){
// Convert the template into pure JavaScript
compledStr = jQuery.trim(markup)
.replace( /([\\'])/g, "\\$1" )
.replace( /[\r\t\n]/g, " " )
.replace( /\$\{([^\}]*)\}/g, "{{= $1}}" )
.replace( /\{\{(\/?)(\w+|.)(?:\(((?:[^\}]|\}(?!\}))*?)?\))?(?:\s+(.*?)?)?(\(((?:[^\}]|\}(?!\}))*?)\))?\s*\}\}/g,
//省略部分模板替换语句
}
return new Function("jQuery","$item",
// Use the variable __ to hold a string array while building the compiled template. (See https://github.com/jquery/jquery-tmpl/issues#issue/10).
"var $=jQuery,call,__=[],$data=$item.data;" +
// Introduce the data as local variables using with(){}
"__.push('" + compledStr +
"');return __;"
)
}
在doT.js源码中没有用到with这类消耗性能的语句,与此同时doT.js选择先将模板编译结果返回给开发者,这样如要重复多次使用同一模板进行渲染便不会反复编译。
仅25行的模板:tmpl
1 | (function(){ |
阅读这段代码会惊奇的发现,它更像是baiduTemplate精简版。相比baiduTemplate而言,它移除了baiduTemplate的自定义语法标签的功能,使得代码更加精简,也避开了替换用户语法标签而带来的性能消耗。对于doT.js来说,性能问题的关键是with语句。
综合上述我对tmpl的源码进行移除with语句改造:
改造之前性能:

改造之后性能:

如果读者对性能对比源码比较感兴趣可以访问 https://github.com/chen2009277025/TemplateTest 。
总结
通过对doT.js源码的解读,我们发现:
- doT.js的条件判断语法标签不直观。当开发者在使用过程中条件判断嵌套过多时,很难找到对应的结束语法符号,开发者需要自己严格规范代码书写,否则会给开发和维护带来困难。
- doT.js限制开发者自定义语法标签,相比较之下baiduTemplate提供可自定义标签的功能,而baiduTemplate的性能瓶颈恰好是提供自定义语法标签的功能。
很多解决我们问题的插件的代码往往简单明了,那些庞大的插件反而存在负面影响或无用功能。技术领域有一个软件设计范式:“约定大于配置”,旨在减少软件开发人员需要做决定的数量,做到简单而又不失灵活。在插件编写过程中开发者应多注意使用场景和性能的有机结合,使用恰当的语法,尽可能减少开发者的配置,不求迎合各个场景。